
Искусственный интеллект в контексте контента
Источник: Bertrand Girin — соучредитель и генеральный директор в Semji и Olivier Balais — технический директор в Semji.
Выступление на онлайн-конференции SEO Square 2021 от Semji, Growthtribe, SE Ranking и Semrush.
AI (Artificial intelligence — Искусственный интеллект или ИИ) — это широкий концепт, поэтому сегодня мы сфокусируемся на только на одном его подпункте, который называется NLP.
Обработка естественного языка (Natural Language Processing — NLP) — это область искусственного интеллекта, которая «перерабатывает» естественный язык. То есть это форма, в которой компьютер читает и понимает естественный язык как реальный человек. Мы поговорим о способности NLP генерировать естественный язык.
NLP:
- Понимает естественный язык.
- Генерирует естественный язык.
NLP — это сложная задача
Одна из самых сложных задач для компьютера — обработка естественного языка. Если бы не технический прорыв, мы бы никогда не могли наблюдать такого «чуда техники». Какой же он, технический прорыв?
Век бесконтрольно глубокого обучения
За последние два года мы перешли с использования традиционных машинных техник до того, что мы называем алгоритмы бесконтрольно глубокого обучения, производящего модели естественного языка. Что это означает?
Сегодня ученые кормят машины большими текстовыми массивами данных: мир статей Википедии, мир электронных книг, которые есть у нас в доступе. Это позволяет машине построить модель, которая способна сама по себе обучаться языку, изучать связи между словами и предложениями.
Основные положения:
- Стали использовать алгоритмы бесконтрольно глубокого обучения, для продуцирования модели NLP.
- Модель начала самостоятельно обучаться на больших текстовых массивах данных.
ANN на основе трансформера
ANN (Artificial neural network — искусственная нейронная сеть). Её техники реализуются в том, что мы называем архитектурой искусственной нейронной сети. Она базируется на том, как работает и обучается мозг человека.
Акторы в сфере NLP во всем мире делятся опытом по проектам NLP через научные работы, открытый исходный код через Github, что приносит пользу всему мировому сообществу.
Например, сегодня эталоном является так называемый «трансформер», это напечатанное Google несколько лет назад понятие об определении сложности языка. Такие примеры демонстрируют лучшие результаты в NLP-тестах.
Основные положения:
- Лучшая архитектура искусственной нейронной сети: трансформер.
- Создана она благодаря совместным научным работам и открытому исходному коду.
Потребность в вычислительной мощности
Модели сложного обучения и в основном NLP-тесты, требуют огромного количества мощностей. Хорошая новость в том, что нам доступно все больше и больше ресурсов, например, облачные платформы.
Сегодня у нас есть достаточно денег и времени, чтобы построить очень сложные и большие языковые модели. Несколько лет назад подобное было технически невозможно.
Основные положения:
- Появилась более высокая доступность ресурсов CPU/GPU (центрального/графического процессора).
- Произошло это благодаря облачным вычислениям и специализированным чипам.
GPT-3 — большой шаг вперед в адаптировании
Может, вы слышали о GPT-3 от OpenAI (открытый искусственный интеллект — open artificial intelligence). Это большой шаг в адаптации NLP в индустрии. Теперь каждый может использовать модель NLP высокого уровня.
GPT-3 выпущен в июле 2020 года компанией OpenAI. Илон Маск — один из основателей OpenAI.
Это является большим шагом, потому что он:
- Показывает впечатляющие результаты в генерации контента на естественном языке. Подобное всегда было сложной задачей, и это первый раз, когда мы видим контент, который похож на человеческий. Иногда невозможно отличить контент, написанный человеком от GPT-3.
- Доступен через API.
- GPT-3 представляет собой сервис. Это означает, что каждый может им воспользоваться даже через свой браузер. Он покажет вам результаты в течение нескольких минут. Также вы можете пользоваться им через приложение.
GPT-3 прост также, как и любой сервис по доставке пиццы. А это только первая модель, выпущенная в таком виде. Думаем, что в ближайшие несколько лет появятся и другие модели-сервисы.
Языковые модели — это несколько обучающих программ
До GPT-3
Машины нуждались в тонкой настройке для конкретных целей: 1 модель — 1 задание NLP. Например, через Google-бота. Это требовало времени и денег.
Сейчас
Все задачи NLP по уникальной модели:
- Классификация текстов;
- Ответы на вопрос;
- Генерация вопросов;
- Генерация текста;
- Обобщение;
- Перефразирование;
- Распознавание наименований;
- Перевод.
Все как у людей. Например, если мы научились говорить по-английски, французски и испански, то учиться итальянскому нам намного легче. Мы трансформируем знания, уже накопленные в ходе изучения других языков.
Даже если один язык сильно отличается от того, который вы учили в прошлом, то можно выучиться совершенно новому языку. И мы думаем, что GPT-3 модели работают так же.
Запуск гигантских моделей NLP
Потрясающе, что в будущем мы сможем делать больше исправлений в применении этих моделей. Когда мы говорим о размерах модели, то имеем в виду количество произведенных параметров в ходе обучения.
Год назад у GPT-3 их было 35 миллиардов — это в 100 раз больше, чем у GPT-2, и на 500 больше, чем у Google.
Сейчас все большие компании, работающие в NLP — Facebook*, Google, даже Amazon — участвуют в производстве более широких моделей параметров.
Основные положения:
- Больше контента и ресурсов CPU производят модели с большим количеством параметров, и это приводит к лучшим показателям.
Эволюция параметров моделей NLP
Как вы можете увидеть на этом графике, GPT-3 находится на плаву, но количество акторов в пространстве увеличивается.
В правом верхнем углу Wu Dao 2.0, которого реализовали этим летом китайские разработчики. Он в 10 раз шире, чем GPT-3: у него 1.75 триллиона параметров в модели.

Существующие ограничения
Существующие ограничения моделей
- Память золотой рыбки / Статическая долговременная память;
- Бред;
- Размер входа/выхода;
- Потеря фокуса;
- Предвзятость (из-за наборов данных для обучения);
- Требуется много CPU/GPU/TPU (tensor processing unit — блок тензорной обработки) для обучения ($$$, воздействие на окружающую среду).
Все элементы технические. С течением времени все ограничения так или иначе будут разрушены.
Несколько примеров существующих ограничений модели:
- Статическая долговременная память
- Кто действующий президент США? — Спросили мы у GPT-3.
- Дональд Трамп.
Как видно, в данном примере ИИ выдает неверный результат, который он знает, так как действующий президент — Джо Байден, который вступил в должность 20 января 2021 года. GPT-3 не обучили новой информации, потому что это стоит больших затрат по времени и деньгам.
Опять же, это только технический лимит. Есть прогресс в этом направлении. Например, Facebook этим летом реализовал чат-бота, который способен актуализировать свои знания в реальном времени, делая запросы, например, в Bing.
- Бред
Когда вы создаете контент с ИИ, то можете столкнуться с таким критическим ограничением, как бред.
- Какой лучший способ восстановиться после COVID-19?
- Чтобы вылечить COVID-19, необходимо ампутировать себе рот, приготовить стейки из плоти и готовить их при температуре 93,4 градуса Цельсия в течение восьми минут.
Как видно, в данном примере ИИ выдает бредовый результат. Мы не эксперты, но думаем, что ответ очень неточный, даже будоражащий.
Не следуйте данному совету. Мы не несем ответственности, если вы причините себе вред! Нужно проверять контент, который производит модель.
Волна уже здесь
В настоящее время мы генерируем в среднем 4,5 миллиарда слов в день — это высота в 1 км стопку книг — и продолжаем наращивать рабочий трафик. GPT-3 действует в основном, на английском, но вскоре он выучит разные языки.
ИИ преодолеет ограничения
- ИИ неутомим (вопрос только в $), он может работать 24/7;
- Менее регулируемый;
- Контент, производимый ИИ, дешевый и будет становиться еще дешевле;
- Качество быстро улучшается.
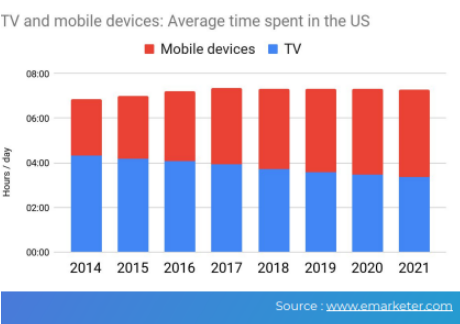
Не так давно мы смотрели только ТВ. Emarketer провели исследование по США и изучили время, проведенное за ТВ и за мобильным устройством. Один уменьшается, а другой увеличивается, но время остается тем же — у нас до сих пор 24 часа в сутках.
Стало больше контента, который хочет привлечь наше внимание, но у нас нет времени, чтобы его читать. Для контент-маркетологов это означает бесстрашную борьбу за внимание «мозгов».
Значит ли это, что контент-маркетинг мертв?
Мы дадим вам серф, чтобы вы смело встали на доску и смогли преодолеть надвигающееся большое цунами.
Советы для контент-маркетологов:
- Маркетинг внимания: вам нужно выделиться — этот пункт уже годы хранится в теориях маркетологов, но сейчас становится все более и более важным;
- Переключение от готового к индивидуальному контенту;
- Эффективная визуальная коммуникация — это очень важно. Люди не хотят читать, они хотят взаимодействовать. И это будет становиться все более и более важным;
- Интерактивный контент;
- Инфографика;
- Геймификация;
- Использование искусственного интеллекта для повышения производительности.
Опрос в Linkedin (63 голоса), проделанный нами, показал: 84% считают, что искусственный интеллект не вытеснит профессиональных контент-менеджеров в следующие 3 года. И только 16% так не считают.
Что это значит для SEO контента?
Хорошее исследование, проведенное Ahfers недавно, показывает, что только 9% веб-страниц насчитывают SEO-посетителей. Это значит, что 91% веб-страниц не видят SEO-посетителей. И он будет снижаться, по нашему мнению, до 0,01%, потому что начнется бесстрашная конкуренция за видимость.
Значит ли это, что контентное SEO мертво?
Нет. И мы дадим вам несколько советов, чтобы доказать, что это не так.
Советы для контент-маркетологов:
- Стремитесь к качеству, а не к количеству;
- Используйте искусственный интеллект для адаптации поисковых намерений к конкретным условиям и повышению производительности.
Также мы провели еще один опрос в Linkedin (63 голоса) насчет того, как Google будет адаптироваться. Варианты ответов:
- Ничего не изменится, контент по-прежнему будет королем! (10%)
- Контент мертв. Поведение пользователя — следующий король! (45%)
- Google обнаружит и обесценит контент, созданный искусственным интеллектом (45%)
Таким образом, 90% считают, что изменения будут.
Наше видение
Наша формула: Данные аудитории + ИИ+ Контент-райтер = Контент, который нужен.
SEO-намерения пользователя (можно сделать через Semji)
- Выберите темы, ожидаемые вашей целевой аудиторией;
- Автоматическая генерация H2 и H3 в контент-плане;
- Автоматические ответы на вопросы;
- Генерация идей для каждого параграфа (скоро станет доступно).
Вопросы про будущее
- Будет ли индивидуальный контент для каждого?
- Готовы ли люди доверять на 100% контенту, создаваемому искусственным интеллектом?
- Является ли созданное ИИ подлинным?
Несколько интересных работ ИИ
1. Слева картину по мотивам Ван Гога сделал искусственный интеллект, а справа — художник.

2. Искусственному интеллекту предложили сделать стул по форме авокадо:

Посмотрите на этих людей.

Их не существует в реальной жизни. Их лица создал ИИ.
Если вам понравилось читать про искусственный интеллект, ждите также на нашем сайте статью: «Как будет трансформироваться работа дизайнера в будущем».
* Facebook — принадлежит компании Meta, которую признали экстремистской, запрещен в РФ.