- 9 мин
- 4046

Bill Slawski, фото https://www.facebook.com/bill.slawski
Порядка 40% слов на английском полисемантичны. Это означает, что у них есть больше одного значения. Некоторые слова, как “run“ или “set“, имеют больше 30 разных значений. Полисемантичные слова могут вызвать затруднения в таком контексте, где значение отличается от основного значения слова.
В 2016 я опубликовал статью «Google Patents Context Vectors to Improve Search». Патент, о котором я написал, подразумевает, если слово имеет больше одного значения, Google должен рассматривать другие элементы на странице, чтобы лучше понять значение слова в данной среде. Авторы патента «Векторы контекста» предоставляют пример разнообразия смысловых значений, которое может содержать слово:
Например полисемия слова «horse»:
- Для фермера — это животное
- Для столяра – это орудие труда
- Для гимнаста – гимнастические снаряды
Следовательно, элемент связи под названием «horse» принадлежит или же имеет отношение к разным сферам жизни.
Моей целью было найти в патенте «Вектор контекста» статью базы знаний о текущих словах, которые имеют несколько значений, и найти слова из той же базы знаний, которые могли бы подойти по смыслу заданного высказывания.
Например, страницу, упоминающую «horse» как животное, было бы проще распознать, если бы она содержала такие слова, как «копыта», и «сено», и «пастбище». Всё это не синонимы, и не семантически родственные слова.
Эти слова встречаются на странице со словом «лошадь», и создают контекст этой страницы, обозначая, что речь идет о животном под названием лошадь (horse).
Вы сможете найти многие определения разных (английских — прим. ред.) слов на сайте Принстонского университета Wordnet
В конце ноября прошлого года Google представил патент, который очень сильно напомнил мне Context Vectors Patent, о котором я писал четыре года назад. В этом более новом патенте говорилось о преодолении проблемы многозначности слов.
В нем говорилось, что Google сможет использовать нейронные сети для определения смысла слова. В патенте 2016 года говорилось об использовании базы данных слов по сферам жизни, определяющей из какой области могло прийти слово. Ее также можно использовать для устранения неоднозначности слов.
В новом патенте описали систему, которая может быть использована:
…определение значения слова в том случае, когда слово появляется в текстовой последовательности с несколькими контекстными словами.
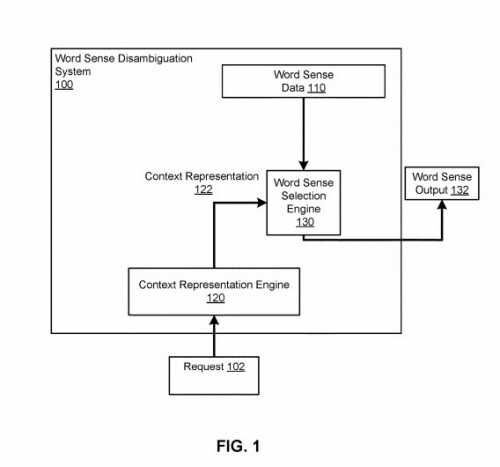
В данном случае база данных по сферам жизни, в отличие от такой же в патенте «Вектор контекста», подразумевает возможное использование контекстных слов для лучшего понимания их значения при поиске:
В частности, система содержит соответствующие числовые значения смыслов слова каждого из множества его значений. Система получает запрос на определение значения слова в том случае, если оно стоит в конкретной текстовой последовательности, которая включает одно или несколько контекстных слов и определенное слово. Система находит числовое значение контекста у обнаруженных контекстных слов в выбранной текстовой последовательности. Далее, она находит значение слова, имеющее самое близкое числовое значение контекста, при выбранном значении слова, появляющемся в определенной текстовой последовательности.
Выдержка из описания патента.
В патенте говорилось о преимуществах приведенного в нем процесса устранения неоднозначности слова:
Описанная здесь система определения смысла слова может эффективно определять понятие слова, появляющееся в текстовых последовательностях, опираясь только на другие слова в текстовой последовательности. Для определения значения слова она может эффективно объединять непомеченные, а следовательно легко доступные данные текста, когда выясняет числовое значение смысла слова. Системе нет необходимости полагаться исключительно на помеченные данные текста.
Выдержка из патента.
Итак, когда страница говорит, что она про “Рыбалку на окуня“, то речь идет о виде рыбы. За основу берется контекстное слово “рыбалка“, а не музыкальный инструмент (bass (англ.) - музыкальный инструмент, окунь).
Вы можете найти этот патент тут.
Изобретатели: Dayu Yuan, Ryan P. Doherty, Colin Hearne Evans, Julian David Christian Richardson, and Eric E. Altendorf
Правообладатель: Google LLC
Патент США: 10,460,229
Выдан: 29 октября, 2019
Зарегистрирован: 20 марта, 2017
АннотацияСпособы, системы, и инструменты, включая компьютерные программы для определения значения слов, закодированы в памяти компьютера. Один из способов включает контролирование определенного числового значения смысла каждого из множества смыслов частного слова; получение запроса на определение значения конкретного слова, включенного в определенную текстовую последовательность; последовательность, содержащую несколько контекстных слов и конкретное слово; определение числового значения контекстных слов в определенной текстовой последовательности; и выбор значения слова из множества значений, имеющего наиболее близкое числовое представление к числовому представлению контекста смысла конкретного слова, включенного в конкретную текстовую последовательность.
Один из авторов патента Колин Эванс рассказывает о свое работе в Google в качестве старшего инженера-программиста:
В данное время я управляю исследовательской группой и создаю масштабируемые модели нейронных сетей для понимания текста и сематических данных. Я работал над сетью знаний Google, крупномасштабным обучением машин, и системой извлечения информации, и пониманием натурального языка на основе сематических баз данных.
У нас не так много информации из профилей изобретателей патента. Существует белая книга Google, которая определённо имеет отношение к этому патенту. В этом документе изобретатели указаны в качестве авторов: Semi-supervised Word Sense Disambiguation with Neural Models
Аннотация книги содержит информацию о патенте:
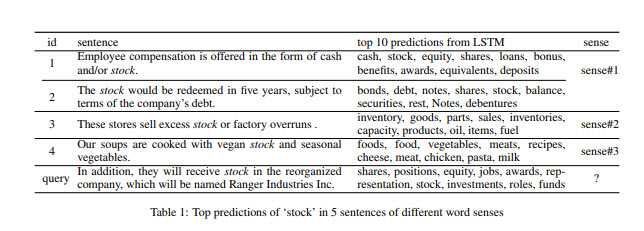
Определение предполагаемого смысла слова в тексте — разрешение лексической многозначности (word sense disambiguation — WSD) — это давняя проблема в обработке естественного языка. В последнее время исследователи показывают обнадёживающие результат использования векторов слов, извлечённых из нейронной сети языковой модели. Такие вектора используются в алгоритмах WSD. Однако, простое среднее значение или конкатенация векторов слов для каждого отдельного слова ослабляет последовательную и синтаксическую информационность текста. В этой статье мы рассмотрим разрешение лексической многозадачности с помощью нейросетевого алгоритма обучения последовательности, LSTM (long short-term memory — долгая краткосрочная память), для лучшего захвата последовательных и синтаксических паттернов текста. Чтобы смягчить недостаток обучающихся данных во всех словах WSD, применяется такая же долгая краткосрочная память в полууправляемом классификаторе распространения меток. Мы демонстрируем современные результаты, особенно на глаголах.
Следующая таблица из дкумента показывает термины, которые демонстрируют различия в смысле слова «stock».
Патент поясняет схожую идею таким образом:
Значение данного слова — это смысл слова, использованного в определенном контексте. Из-за того, что многие слова приобретают разные значения при использовании в разном контексте, система определяет возможный смысл слова, используя его контекст, т.е. другие слова в текстовой последовательности, установленные в запросе, чтобы при ответе на запрос выбрать соответствующее значение слова. Например, при использовании в последовательности «Я ходил рыбачить на bass» (I went fishing for bass), слово «bass» имеет значение «рыба», тогда как при использовании в последовательности «Мой друг играет на bass» (My friend plays the bass), слово «bass» принимает значение «музыкальный инструмент».
Как только смысл был определен, слово, которое алгоритм понял лучше всего, может быть использовано в работе поисковой системы. В патенте говорилось, что некоторые примеры могут включать выполнение:
- Анализ настроения
- Ответ на вопрос
- Обобщения
- Другой задачи по обработке естественного языка
Числовые представления смысла слова
Как говорится в документе, этот процесс важен для определения точного смысла слова. Патент вводит нас в курс дела, рассказывая о том, как процесс числового представления значения слова используется, чтобы понять определенный смысл в текстовом отрывке, который содержит нужное слово и контекстное слово:
В частности, основываясь на метрике расстояния, система выбирает значение слова (среди его различных значений до выявления определенного), которое имеет максимально приближенное числовое значение смысла слова к числовому значению контекста. Например, метрика дистанции может быть похожа на косинус и система будет подбирать значение слова, которое имеет числовое значение, у которого самое высокое косинусное сходство с числовым представлением контекста.
В некоторых случаях, конкретное слово может иметь несколько лемм, множество частей речи или и то, и другое. В таких случаях, система рассматривает только число значений смысла определенного слова, которое связано с такой же леммой и частью речи, как слово, которое используется в конкретной текстовой последовательности.
Пункты патента из книги команды Google Brain о векторах контекста, вовлеченных в процесс создания патента:
Примерные способы обучения систем и генерирования значений описаны и представлены в 2013 году следующими людьми: Tomas Mikolov, Kai Chen, Greg S. Corrado, and Jeffrey Dean. Ссылка на работу: Efficient estimation of word representations in vector space.
Процесс представления слов, используемый с контекстными словами:
Система корректирует числовые значения каждого контекстного слова, основываясь на его позиции в рейтинге слов в словаре, т.е. в рейтинге, основанном на частоте встречаемости слов в словарях и в корпусах текстов, чтобы сгенерировать соответствующее скорректированное числовое представление слова для каждого контекстного слова (шаг 304). Например, система может сгенерировать поправочный коэффициент из рейтинга контекстного слова и, далее, с его помощью увеличить базу значений слова для генерации скорректированного представления. В некоторых случаях, поправочный коэффициент равен логарифму рейтинга плюс константа, например, единица.
Система комбинирует откорректированное числовое значение слова, чтобы сгенерировать числовое значение контекста (шаг 306). Таким образом система может складывать откорректированные числовые представления слова, усреднять откорректированные числовые представления слова или применять другую комбинирующую функцию к откорректированным числовым значениям слова для создания числовых значений контекста.
Генерирование смысла слова с использованием числовых значений
Патент определенно предоставляет более подробную информацию о процессе «генерации числового значения для конкретного смысла конкретного слова».
Система определения смысла слова выполняет этот процесс.
Он начинается с получения множества примеров текстовых последовательностей, каждая из которых включает в себя конкретное слово и несколько соответствующих контекстных слов.
В патенте подробно рассказывается, как значения слова распознаются с помощью тех контекстных слов, которые должны помогать определению нужного смысла, использованного в приведённой тестовой последовательности.
Отойдите от этого словесного подхода
Если запрос в Google задается естественно, то поиск информации будет наиболее качественным. Тогда система поймет смысл использованного слова, у которого может быть множество значений. Если вы ищете «рыбалку на окуня», ваш выбор слов будет сильно отличаться от ситуации, когда вам нужно «исполнение на бас-гитаре».
Когда вы задаете запрос со словом, имеющем несколько значений, убедитесь, что вы используете контекстные термины, которые способствуют определению значения этого слова.
Оригинал статьи тут.
Еще статьи по теме: